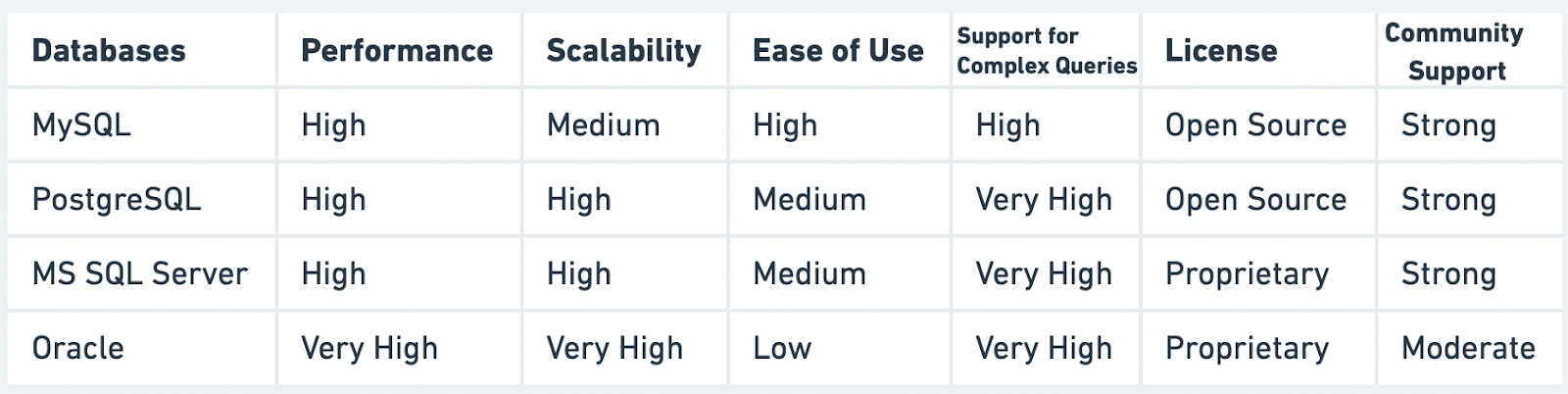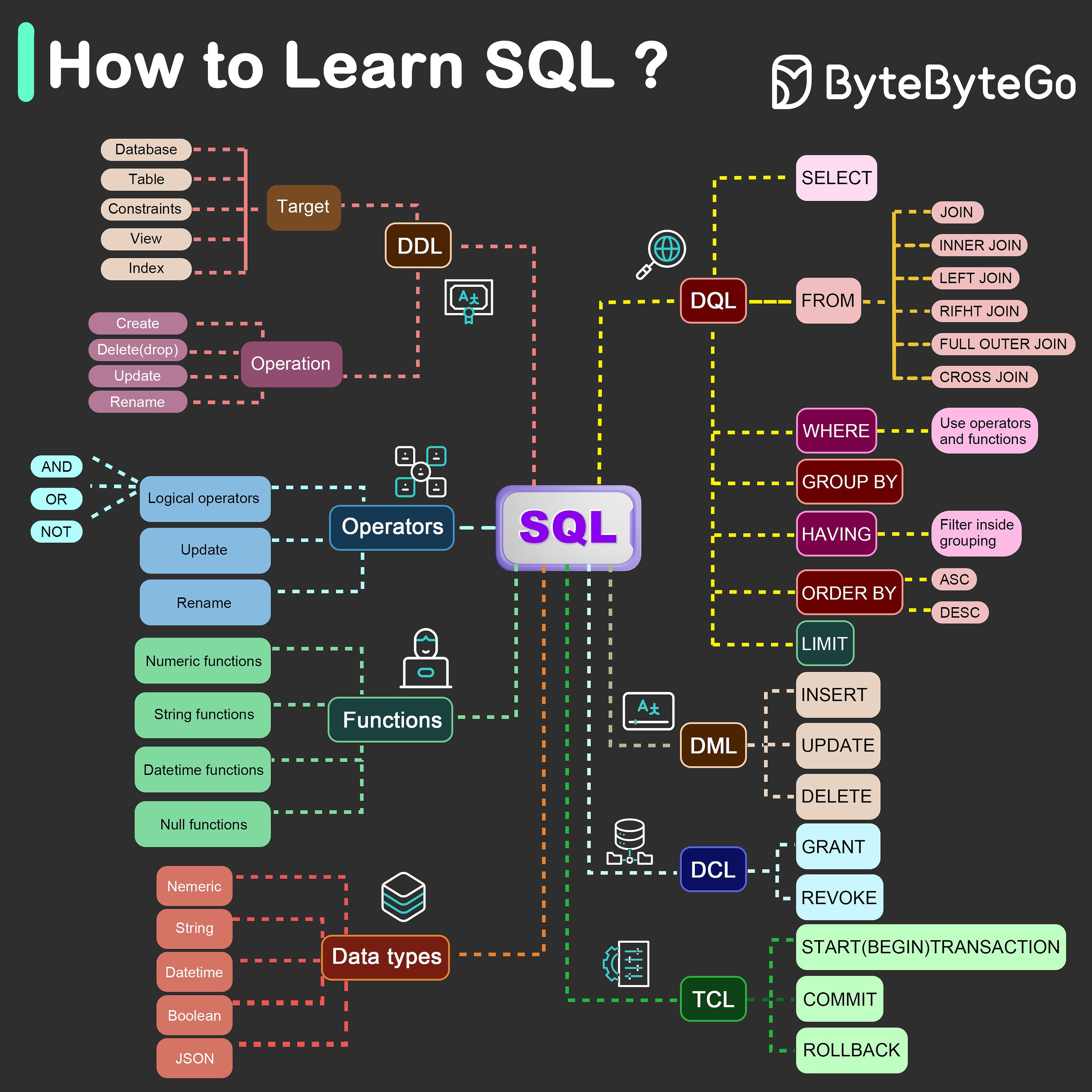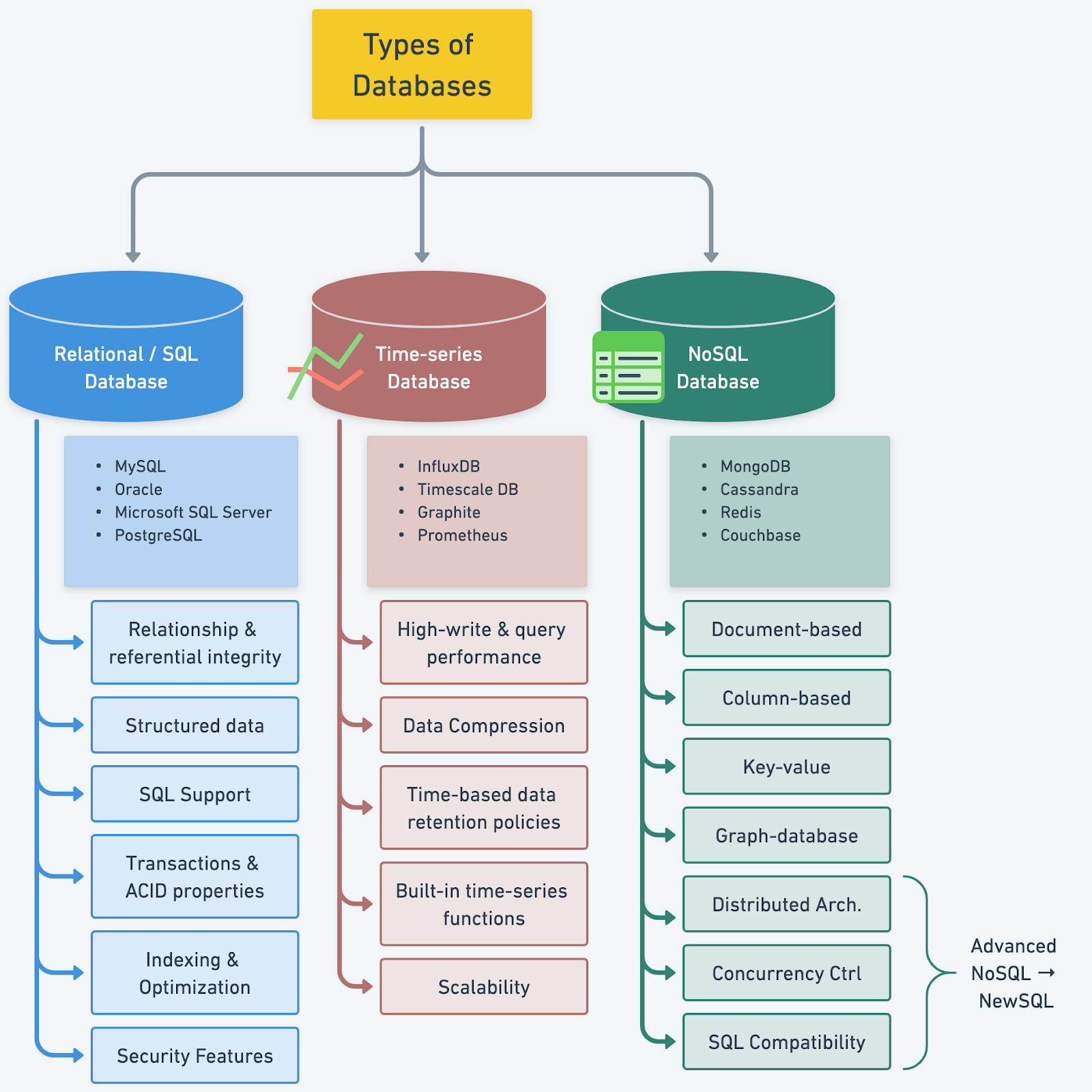
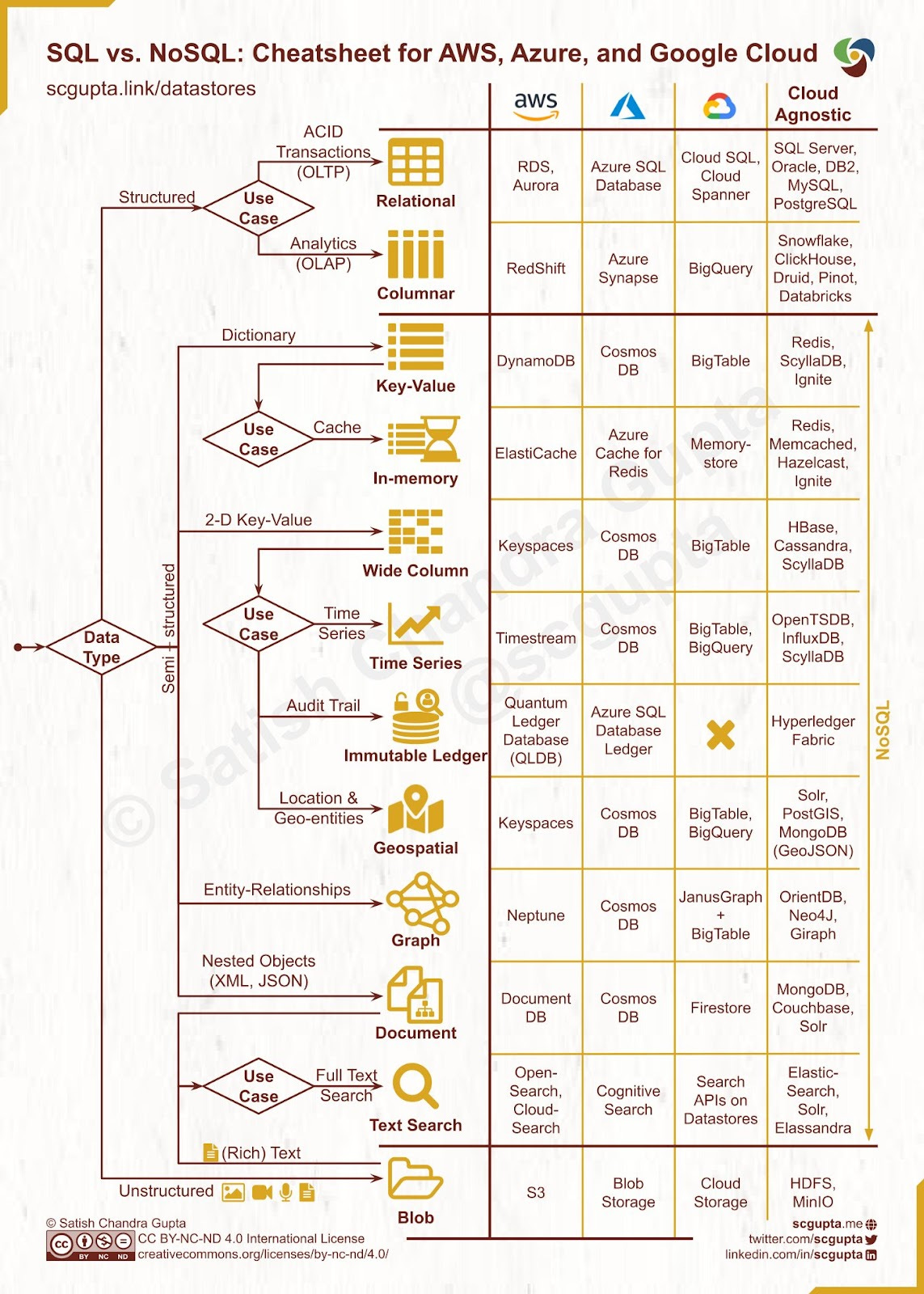
Relational Databases (RDBMS)
- SQL = Structured Query Language
- Examples: MySQL, PostgreSQL, Oracle, SQL Server
- Features:
- Table-based.
- Uses SQL (Structured Query Language) for data manipulation.
- Supports ACID (Atomicity, Consistency, Isolation, Durability).
- Advantages:
- Strong guarantees of data consistency and integrity.
- Widely known and supported.
- Good performance for complex transactions.
- Disadvantages:
- May be less efficient for large volumes of unstructured data.
- Horizontal scalability can be complex.
- Use cases:
- Financial systems.
- E-commerce applications.
- Enterprise resource planning (ERP) systems.
- Inappropriate cases:
- Applications that require extreme horizontal scalability.
- Highly unstructured or semi-structured data.
NoSQL Databases
- NoSQL = Not Only SQL
- Examples: MongoDB, CouchDB
- Features:
- Document-based.
- Uses JSON or BSON for data storage.
- Does not require a fixed schema.
- Advantages:
- Flexibility in data schema.
- Good horizontal scalability.
- Suitable for semi-structured data.
- Disadvantages:
- May not offer full ACID guarantees.
- Can be more complex to manage data integrity.
- Use cases:
- Big Data applications.
- Social networks and user-generated content storage.
- Mobile and web applications.
- Unsuitable cases:
- Complex transactional systems.
- Applications that require strong data consistency guarantees.
Key-Value Databases
- Examples: Redis, Riak
- Features:
- Simple data structure (key-value pairs).
- High performance for read and write operations.
- Advantages:
- Low latency.
- Easy to scale horizontally.
-
- Disadvantages:
- Limited functionality for complex queries.
- Not suitable for highly relational data.
- Use cases:
- Session caching.
- Real-time recommendation systems.
- Event counting and metrics.
- Unsuitable cases:
- Complex and relational queries.
- Data that requires ACID transactions.
Graph Databases
- Examples: Neo4j, OrientDB
- Features:
- Data structure based on graphs (nodes, edges and properties).
- Ideal for representing and querying complex relationships.
- Advantages:
- Excellent performance for graph queries.
- Innately suited for highly connected data.
- Disadvantages:
- Can be difficult to integrate with legacy RDBMS-based systems.
- Less mature compared to RDBMS in terms of tools and support.
- Use cases:
- Social networks.
- Recommender systems.
- Identity management and access control.
- Unsuitable cases:
- Applications with low connectivity between data.
- Large financial transactions.
Columnar Databases
- Examples: Apache Cassandra, HBase
- Features:
- Column-oriented storage.
- Excellent for massive data read/writes.
- Advantages:
- Highly scalable.
- Good performance for bulk read operations.
- Disadvantages:
- Can be complex to configure and manage.
- Not ideal for ACID transactions.
- Use cases:
- Real-time data processing and analytics.
- Data warehousing.
- Unsuitable cases:
- Systems that require ACID transactions.
- Highly relational data.
In-Memory Databases
- Examples: Redis, Memcached
- Features:
- Data storage directly in RAM.
- Extremely fast data access.
- Advantages:
- Very low latency.
- Ideal for caching and sessions.
- Disadvantages:
- Data can be lost if memory fails.
- Limited by the amount of available memory.
- Use cases:
- Frequent data caching.
- User session systems.
- Unsuitable cases:
- Storage of critical persistent data.
- Large volumes of data that do not fit in memory.
Object-Oriented Databases
- Examples: db4o, ObjectDB
- Features:
- Storage of data as objects.
- Direct integration with object-oriented programming languages.
- Advantages:
- Natural for OO developers.
- Reduces the need for object-relational mapping (ORM).
- Disadvantages:
- Less support and maturity compared to RDBMS.
- May have lower performance for complex queries.
- Use cases:
- Applications with strong object orientation.
- CAD/CAM systems.
- Unsuitable cases:
- Applications that require interoperability with RDBMS.
- Systems with large volumes of relational data.
Temporal Databases
- Examples: InfluxDB, TimescaleDB
- Features:
- Optimized for temporal and time series data.
- Supports advanced temporal queries.
- Advantages:
- Excellent for temporal data analysis.
- Good compression and storage of temporal data.
- Disadvantages:
- Limited to temporal use cases.
- May not be suitable for non-temporal data.
- Use cases:
- Network monitoring.
- Time series analysis.
- Unsuitable cases:
- Data that does not have a significant temporal component.
- Applications that require ACID transactions.
Multi-model Databases
- Examples: ArangoDB, OrientDB
- Features:
- Supports multiple data models (documents, graphs, key-value).
- Flexibility for different data types.
- Advantages:
- Versatility.
- Ability to use the most appropriate model for each case.
- Disadvantages:
- It can be more complex to manage.
- It is not always optimized for a specific type of data.
- Use cases:
- Applications that require flexibility in data storage.
- Prototyping and R&D projects.
- Inadequate cases:
- Critical systems that require specific optimization.
- Applications with very strict data consistency requirements.
Cloud Databases
- Examples: Amazon Aurora, Google Cloud Spanner
- Features:
- Data storage and management in cloud infrastructure.
- High availability and scalability.
- Advantages:
- Reduced infrastructure costs.
- Ease of scalability and maintenance.
- Disadvantages:
- Dependency on the cloud provider.
- Data security and privacy issues.
- Use cases:
- Web and mobile applications that require high availability.
- Startups and companies that want to avoid high initial infrastructure costs.
- Inadequate cases:
- Applications with strict security and data control requirements.
- Legacy systems that are not easily migrated to the cloud.
A.C.I.D
Imagine that you are building a Lego house, and you need to follow some rules to ensure that the house is safe and does not fall apart.
These rules are called A.C.I.D., and they are as follows:
-
Atomicity (A):
- What it is: All the pieces of the house need to be placed at once. If you can’t place all the pieces, then you don’t place any.
- Why it’s important: If you only place half of the pieces, the house will not be safe and may fall apart.
-
Consistency (C):
- What it is: The Lego house must always follow the construction manual. If the manual says that the window has to be on the front wall, it cannot be on the roof.
- Why it’s important: Following the manual ensures that the house is well built and the right way.
-
Isolation (I):
- What it is: If you and your friend are building two different parts of the house, the pieces that one of you places should not interfere with the other.
- Why it’s important: This prevents the pieces from getting mixed up and the construction process from getting confusing.
-
Durability (D):
- What it is: Once you finish building the house and put it away on the shelf, it should stay there until you decide to take it apart.
- Why it’s important: This way, you know that the house will always be the way you left it, even if someone bumps into it.
-
Transactions
Now, think of a transaction as a mission or task to build a part of the Lego house.
A transaction could be, for example, building a wall.
- What it is:
- A transaction is like a task that you need to complete from start to finish.
- If you fail to complete the task, you have to undo everything and try again later.
- Example:
- If you are placing pieces to build a wall, you need to finish the entire wall.
- If you fail to finish, you take all the pieces out and start over later.
- Why this is important:
- Safety: Ensures that you don’t end up with an incomplete wall that could collapse.
- Organization: Helps keep everything in order, without clutter.
To recap:
- A.C.I.D.: These are rules that help ensure that the Lego house (database) is well-built and safe.
- Transactions: These are missions to build parts of the house, which need to be completed from start to finish to ensure that everything is in order.
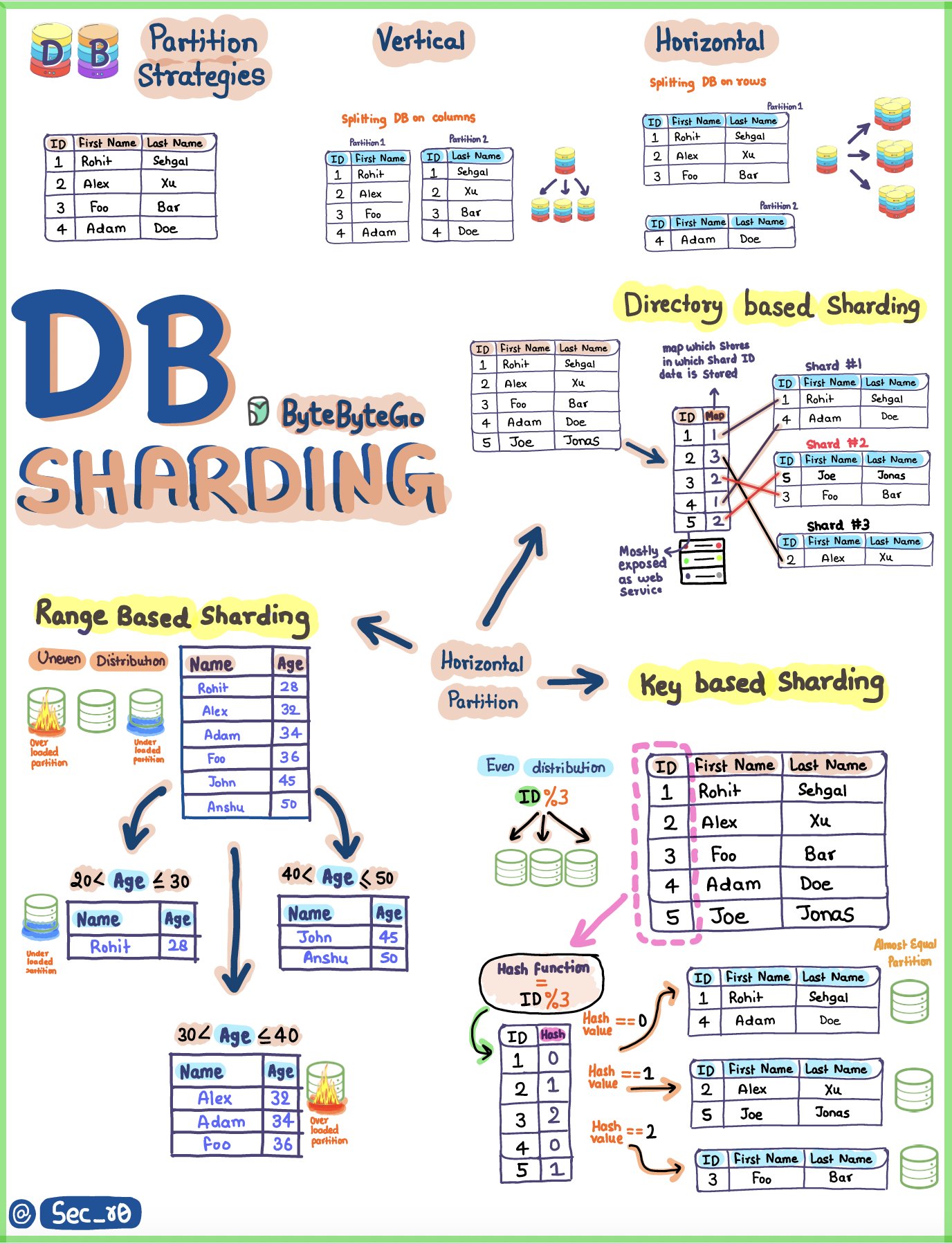
DataBase Sharding
-
It is a database partitioning technique in which a large database is divided into smaller parts, called “shards”. Each shard is a separate database, but together they form the entire storage system.
-
How does sharding work?
- Data partitioning: The database is partitioned based on a sharding key. This key can be, for example, a user identifier, a date range, or any other criteria that makes sense for the application.
- Data distribution: Each shard stores a portion of the total data set. This means that one shard may contain data related to a subset of users, while another shard contains data from another subset.
- Shard management: A shard management system is used to determine which shard a specific piece of data resides in. When a query is made, the system redirects the query to the correct shard.
-
Sharding Use Cases
- Large Web Applications: Social networks, e-commerce, and streaming platforms that have millions of users and large volumes of data. Sharding allows you to scale horizontally and handle large amounts of data and traffic.
- High Availability Applications: Systems that need to be available at all times. With sharding, if one shard fails, the others continue to operate, minimizing the impact on service availability.
- Improved Performance: In systems where latency is critical, such as online gaming or high-frequency trading platforms, sharding can help distribute the load and improve response times.
-
Advantages of Sharding
- Horizontal Scalability: It is easier to add new shards to accommodate data growth, rather than vertically scaling a single database.
- Better Performance: Reduces the load on each shard, resulting in faster queries and efficient use of resources.
- Fault Isolation: Problems in one shard do not affect the others, increasing the resilience of the system.
-
Disadvantages of Sharding
- Complexity: Implementing and maintaining a sharded system is more complex.
- Transactions and Consistency: Maintaining data consistency across shards can be challenging, especially in systems that require ACID (Atomicity, Consistency, Isolation, Durability) transactions.
- Data Redistribution: If the sharding key is not well chosen, it may be necessary to redistribute data across shards, which is a complicated and time-consuming process.
In summary, Database Sharding is a powerful technique for scaling large database systems, especially useful in applications that deal with large volumes of data and high traffic. However, its implementation requires careful planning to deal with the complexity and challenges it introduces.
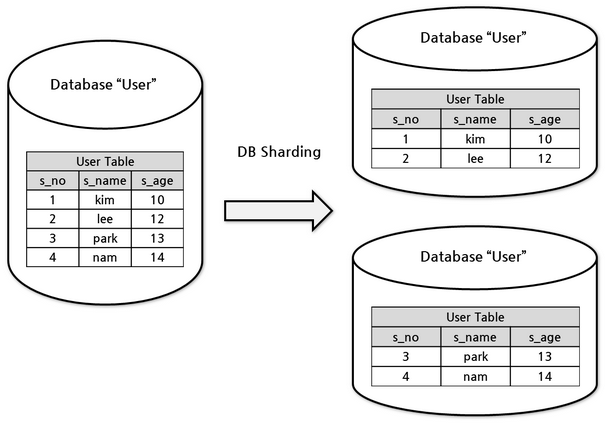
Cloud Databases

SQL